Zwischen Jaguaren und Ziegen – eine kurze Reise durch eine KI-Challenge
von Luisa-Elene Pissors, wiss. Mitarbeiterin im Projekt PowerAImage
15.04.2026
Keywords: Kaggle-Challenge, Computer Vision, Tieridentifikation

Nicht ganz zwei Wochen. Mehr Zeit blieb nicht für die Challenge. Im Kern ging es darum, ein KI-Modell zu entwickeln, das Jaguare auf Bildern wiedererkennt und einzelne Individuen identifiziert. Der Wettbewerb wurde auf der internationalen Plattform Kaggle ausgetragen, auf der Forschende und Entwickler*innen ihre Ansätze miteinander vergleichen. Solche Challenges funktionieren wie offene Wettbewerbe: Es gibt eine übergeordnete Aufgabenstellung, Teilnehmende entwickeln eigene Modelle und wenden sie auf einen gemeinsamen Datensatz an. Eingereichte Ergebnisse werden automatisch bewertet und in einer Rangliste gelistet.
In diesem Fall stammen die zugrunde liegenden Daten aus realen Aufnahmen wilder Jaguare aus dem Pantanal in Brasilien, einer der wichtigsten Regionen für die Jaguarforschung. Ein Großteil der Bilder basiert auf Projekten wie dem Jaguar Identification Project, bei dem über viele Jahre hinweg Fotos von einzelnen Tieren gesammelt und katalogisiert wurden. Während andere Teilnehmende ihre Modelle über Wochen oder sogar Monate hinweg verfeinerten, lief hier in Nürtingen die Uhr von Anfang an schneller. Die Teilnahme diente vor allem dazu, Methoden unter realistischen Bedingungen zu erproben und praktische Erfahrungen zu sammeln. Was in dieser kurzen Zeit entstand, war weniger eine perfekte Lösung; vielmehr entwickelte sich ein intensiver Streifzug durch Methoden, Ideen und Grenzen der KI-Bildverarbeitung. Aus einzelnen Experimenten formte sich dabei nach und nach ein probater Ansatz.
Die feinen Unterschiede
Die Aufgabenstellung der Challenge bestand darin, mithilfe von KI-Methoden einzelne Jaguare anhand von Bildern wiederzuerkennen. Grundlage dafür sind visuelle Merkmale wie die individuellen Fleckenmuster der Tiere. Konkret bedeutet das: Ein Modell wird darauf trainiert, visuelle Eigenschaften eines Jaguars zu erfassen und in eine numerische Darstellung zu übersetzen. Das Modell lernt dabei, Bilder desselben Tieres in der numerischen Darstellung möglichst ähnlich abzubilden, während Bilder unterschiedlicher Tiere voneinander getrennt werden. Auf dieser Grundlage kann das Modell anschließend einschätzen, ob zwei Bilder dasselbe Tier zeigen oder nicht. So lässt sich der bisher sehr aufwendige manuelle Prozess der Identifikation automatisieren und auf große Bildmengen übertragen.
Auf den ersten Blick wirkt die Aufgabe einfach. Schließlich trägt jedes Tier ein einzigartiges Fellmuster, fast wie einen Fingerabdruck. Wie in Abbildung 1 bis 3 zu sehen ist, sind diese Fleckenmuster äußerst charakteristisch und eignen sich gut zur Identifikation. Doch schon nach den ersten Experimenten wurde klar: Diese Muster sind alles andere als leicht zu unterscheiden. Ein und dasselbe Tier kann auf Bildern völlig unterschiedlich aussehen, je nachdem, wie, wo und in welcher Situation es aufgenommen wurde. Mal erschienen die Großkatzen auf den Fotos im Schatten, mal in Bewegung oder aus ungewohnten Perspektiven. Gleichzeitig sind sich verschiedene Jaguare oft verblüffend ähnlich. Die eigentliche Herausforderung bestand also nicht darin, irgendwelche Muster zu finden. Es mussten solche sein, die für ein Exemplar besonders charakteristisch waren und an denen sich Unterschiede möglichst unabhängig von Bildqualität und Motiv festmachen ließen.


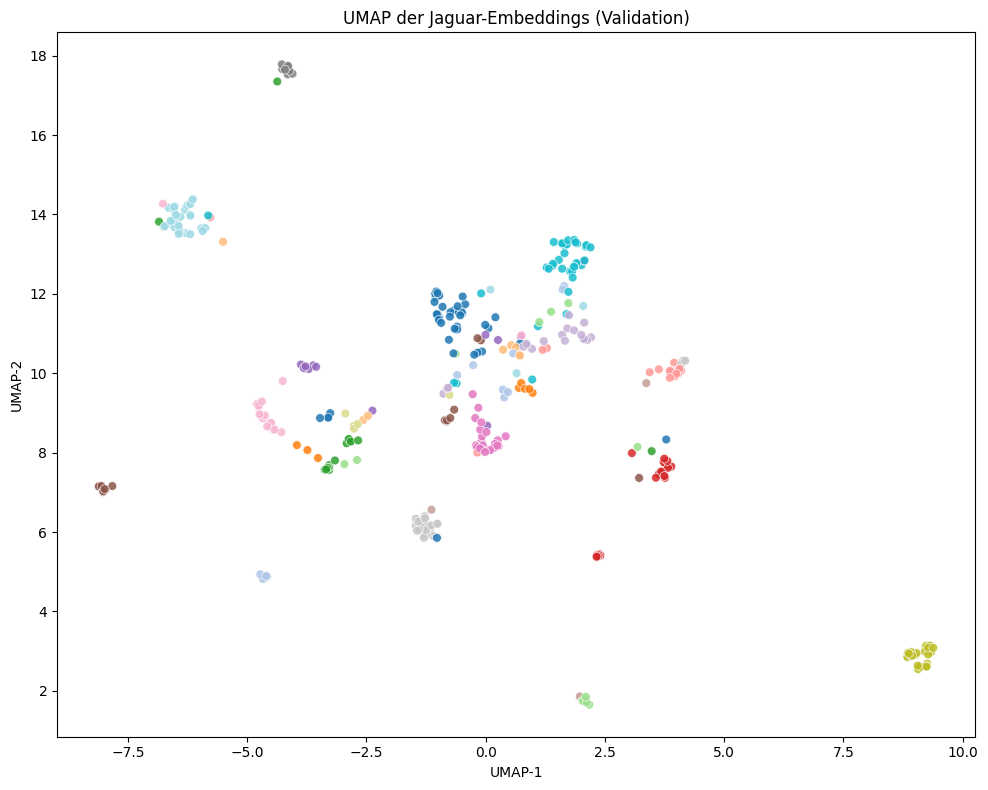
Um die Aufgabe zu meistern, wurden Schritt für Schritt verschiedene Ansätze getestet. Modelle wurden darauf trainiert, aus Bildern sogenannte „Embeddings“ zu erzeugen. Man könnte sagen: Aus jedem Bild entsteht eine Art Zahlencode, der beschreibt, wie ein Jaguar aussieht, ohne das Bild selbst zu speichern. Es entsteht dabei ein Art „Fingerabdruck“ des Bildes. Während wir als Menschen ein Tier über sein Aussehen erkennen, beschreibt das Modell stattdessen Eigenschaften wie Formen, Kontraste oder Muster in Zahlen. Zwei Bilder desselben Jaguars haben dann ähnliche „Zahlencodes“, auch wenn die Bilder visuell auf den ersten Blick unterschiedlich wirken. In Abbildung 4 wird dieser Prozess anschaulich: Jedes Bild entspricht einem Punkt. Bilder desselben Tieres liegen näher beieinander und bilden Cluster, während unterschiedliche Tiere weiter voneinander entfernt liegen. Gleichzeitig wird deutlich, dass eine saubere Trennung nicht immer gelingt. Einige Punkte liegen zwischen den Clustern oder näher an anderen Gruppen, was darauf hindeutet, dass bestimmte Bilder nur schwer eindeutig zuzuordnen sind. Genau hier zeigen sich die Herausforderungen der Aufgabe und mögliche Fehlklassifikationen.
Die Erzeugung solcher „Zahlencodes“ ist ein empfindlicher Prozess. Kleine Änderungen können große Auswirkungen haben. Deshalb wurde gezielt experimentiert: Wie verändern sich die Ergebnisse, wenn Bilder leicht variiert werden, etwa bei schlechter Beleuchtung, Teilansichten oder ungewöhnlichen Perspektiven? Welche Trainingsstrategien helfen dem Modell, ähnliche Tiere besser zu unterscheiden und relevante Merkmale stärker zu gewichten? Und wann beginnt das Modell, sich von irrelevanten Details täuschen zu lassen? Ergänzend wurden verschiedene Ansätze kombiniert, um die Stabilität der Ergebnisse zu verbessern. Dazu gehörten unter anderem unterschiedliche Modellvarianten zur Merkmalsextraktion, angepasste Trainingsstrategien sowie Verfahren, bei denen mehrere leicht veränderte Versionen eines Bildes ausgewertet werden. Mit jedem Versuch wurde das Verhalten des Systems verständlicher.
Nach Ablauf der Bearbeitungszeit wurden die Ergebnisse der Teilnehmenden nicht einfach nach „richtig“ oder „falsch“ bewertet. Stattdessen kam eine Metrik zum Einsatz, die bewusst anders funktioniert: die Identity-Balanced Mean Average Precision. Ihr Prinzip ist einfach: Jedes Tier zählt gleich viel. Ein Jaguar, von dem viele Bilder im Datensatz vorkamen, hat keinen Vorteil gegenüber einem, der nur selten vorkommt. Für das eingereichten Modelle bedeutet das, dass es nicht reicht, die häufigsten Fälle gut zu lösen. Es muss insgesamt ausgewogen arbeiten und auch seltene Individuen zuverlässig erkennen.
Am Ende der Challenge stand kein Spitzenplatz. Vor allem im Vergleich zu Teilnehmenden mit deutlich mehr Zeit, größeren Teams und umfangreicherer Rechenkapazität war das wenig überraschend. Und doch hat sich die Teilnahme gelohnt. Gerade unter diesen Bedingungen lag der Fokus auf dem gezielten Ausprobieren und Verstehen. Innerhalb von nicht ganz zwei Wochen konnten so verschiedene Ansätze getestet und bewertet werden. Viel entscheidender als die Platzierung waren die gewonnenen Erkenntnisse: Welche Methoden funktionieren stabil? Wo liegen typische Probleme? Und wie reagieren Modelle auf unterschiedliche Datenbedingungen?
Von Jaguaren über Ziegen lernen
Genau hier begann der spannende Teil. Nicht nur die Modelle wurden trainiert, auch mein eigenes Verständnis hat sich deutlich weiterentwickelt. Gerade im direkten Ausprobieren zeigt sich, wie KI-Modelle tatsächlich funktionieren. Bei meinem Versuch brasilianische Jaguare mittels KI zu identifizieren, habe ich eine Menge für PowerAImage und meine Arbeit mit Ziegen gelernt. Denn während Jaguare ein klares, individuelles visuelles Muster besitzen, sind Ziegen deutlich schwieriger voneinander zu unterscheiden. Es gibt keine eindeutigen Flecken und keine offensichtlichen „Fingerabdrücke“. Wie in Abbildung 5 zu sehen ist, sind die Unterschiede deutlich weniger offensichtlich als bei Jaguaren. Stattdessen treten subtilere Differenzen in den Vordergrund: Fellstruktur, Körperform oder kleine individuelle Merkmale.
Was ich in der Challenge gelernt habe, ist, eine andere Perspektive einzunehmen: Die Frage, ob eine Identifikation möglich ist, betrachte ich nun viel mehr unter dem Blickwinkel, welche relevanten Merkmale sich dafür besonders eignen und wie sie sichtbar und nutzbar gemacht werden können. Gerade die Erfahrungen aus der Arbeit mit ähnlichen und variierenden Mustern, die sich auf den zweiten, dritten oder vierten Blick aber immer als hoch spezifisch erweisen, bieten hierfür eine wertvolle Grundlage.
Von außen betrachtet war es also eine Challenge, für mich in der Praxis eher ein Experiment. In kurzer Zeit entstanden viele verworfene Ideen, einige funktionierende Ansätze und vor allem ein deutlich besseres Verständnis dafür, wie aus Bildern für KI verwertbare Information gewonnen werden kann. Für das Projekt PowerAImage liegt genau darin der eigentliche Mehrwert. Nicht im Ergebnis, sondern in den Erkenntnissen, die daraus entstanden sind. Und an diesem Punkt werden wir unsere Spurensuche fortsetzen — nicht im Dschungel, sondern im Ziegenstall mit ganz eigenen Herausforderungen.
