Von der Aufnahme zur Erkenntnis – Wie arbeiten wir mit KI-Bildverarbeitung?
KI-Bildverarbeitung setzt sich aus mehreren Schritten zusammen. In der praktischen Forschung werden unterschiedliche Bildformate, Vorverarbeitungsstrategien und Analysemodelle systematisch kombiniert und miteinander verglichen. Je nach Fragestellung kommen verschiedene Merkmalsarten – etwa geometrische Maße, Temperaturverteilungen oder Texturinformationen – sowie unterschiedliche Modellansätze wie Klassifikation, Regression oder Clusteranalyse zum Einsatz.
Der dargestellte Workflow orientiert sich daran, wie wir in PowerAImage forschen. Er bildet eine vereinfachte methodische Grundstruktur ab und ist nicht als starre Abfolge zu verstehen, sondern als flexibel erweiterbares methodisches Rahmenkonzept. Die Struktur folgt einem modularen Ansatz, der unterschiedliche Modelle, Merkmalsdefinitionen und Evaluationsstrategien verbindet. So ist es möglich, neue Datentypen zu integrieren, alternative Modellansätze zu evaluieren und Analyseverfahren an spezifische Forschungsfragen anzupassen. Der entwickelte Ansatz stellt damit eine übertragbare methodische Grundlage dar. Im Folgenden ist die Bildverarbeitungspipeline mit ihren einzelnen Modulen sowie deren experimenteller Weiterentwicklung dargestellt.
Bildaquisation
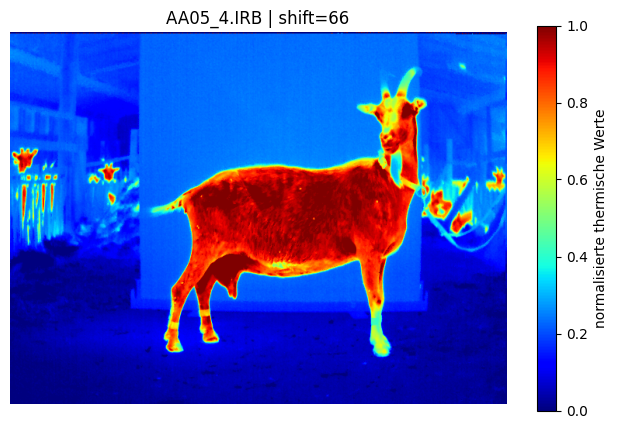
Am Anfang steht die Aufnahme der Rohdaten – etwa durch Farbkameras, Thermografie Kameras oder Tiefensensoren. Im Projekt werden unterschiedliche Bildformate kombiniert, um robuste Informationen zu gewinnen.
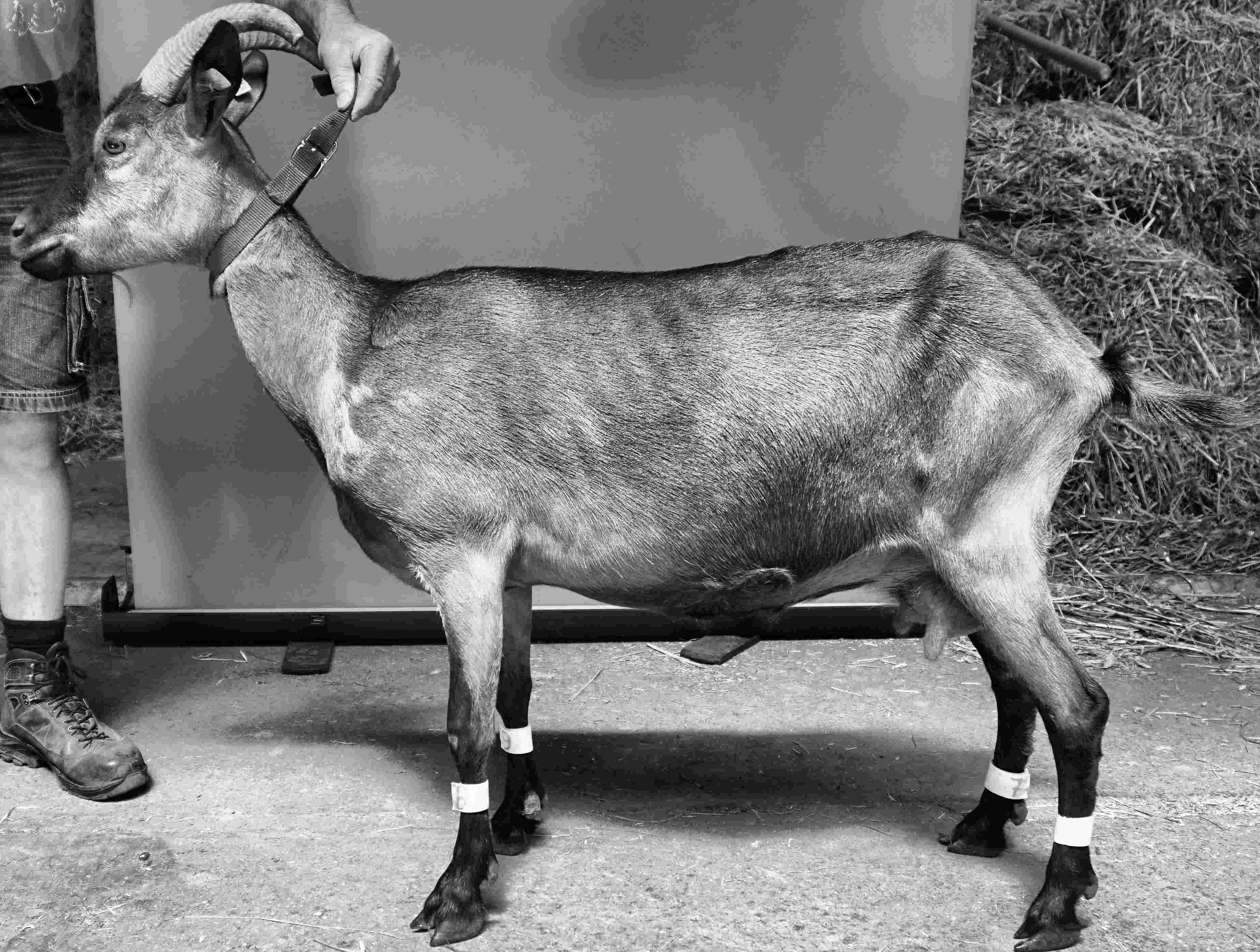
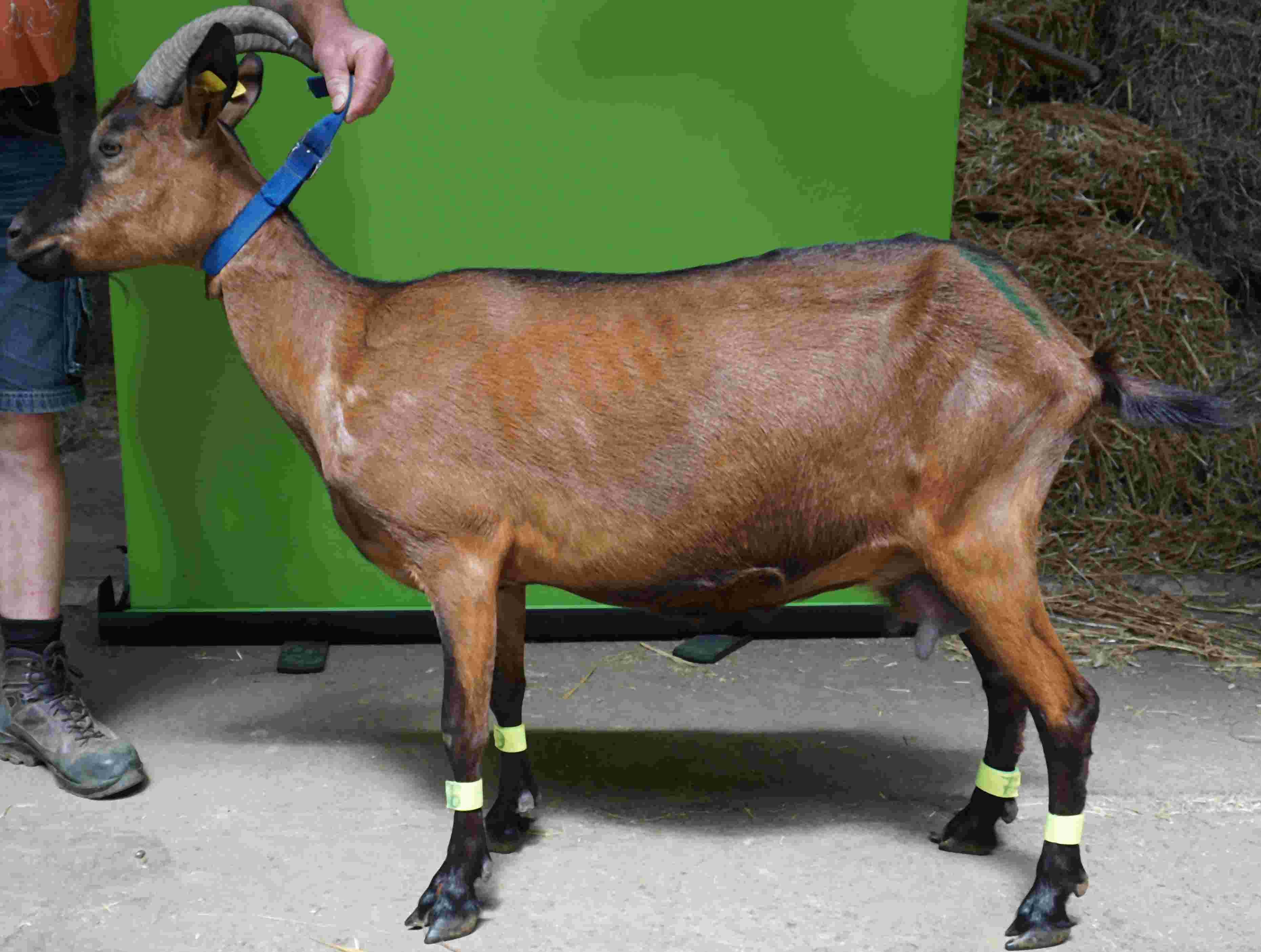
Die derzeitige Pipeline basiert primär auf hochauflösenden RGB-Farbaufnahmen von Ziegen unter kontrollierten Stallbedingungen. Die Bilder dienen als Grundlage für die KI-gestützte Objekterkennung, Segmentierung und geometrische Merkmalsberechnung. Je nach Versuchsaufbau variieren Perspektive, Lichtverhältnisse und Bildausschnitt. Diese Variabilität ist bewusst gewählt, um die Robustheit der Modelle gegenüber realen Einsatzbedingungen zu testen. Erweiterungen um Thermografie- und Tiefendaten sind vorgesehen und werden schrittweise integriert.


Vorverarbeitung
Die Vorverarbeitung bildet die Grundlage für eine robuste und reproduzierbare KI-gestützte Analyse. In diesem Schritt wird die Bildqualität optimiert. Störfaktoren wie Rauschen oder ungünstige Beleuchtung werden reduziert und relevante Strukturen hervorgehoben, ohne die inhaltliche Struktur des Bildes zu verändern. Ziel ist es eine konsistente Datenbasis für nachfolgende Modelle zu schaffen.
Im Projekt PowerAImage wurden mehrere Vorverarbeitungsstrategien implementiert und experimentell evaluiert, mittels derer bei Bedarf die Qualität eines Bildes verbessert werden kann.
1. Signalbasierte Bildoptimierung
Bildnormalisierung und Skalierung: Liegen die Rohbilder in unterschiedlichen Auflösungen und Formaten vor, sind diese für die Weiterverarbeitung in YOLO- und Segmentierungsmodellen zu vereinheitlichen.
Graustufenkonvertierung: Zur Reduktion der Farbkomplexität und Hervorhebung struktureller Intensitätsunterschiede werden RGB-Bilder in Graustufen überführt. Dies dient als Grundlage für kontrast- und kantenbasierte Analysen.
2. Struktur- und Intensitätsanalyse
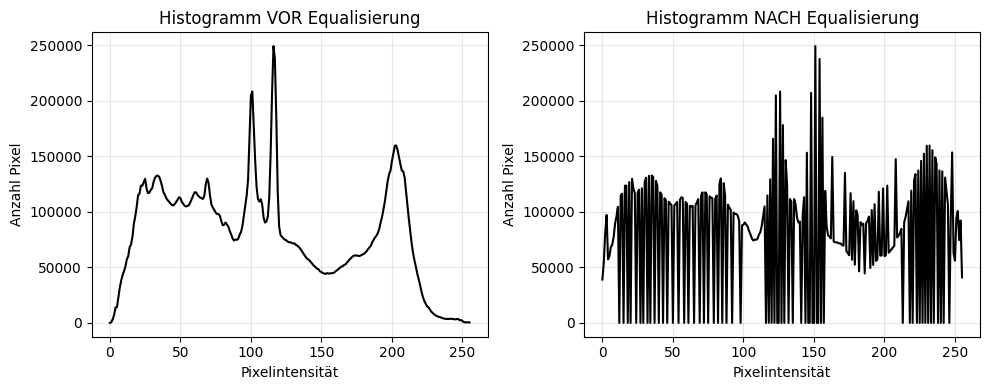
Kontrast- und Helligkeitsanpassung: Variierende Stallbeleuchtung kann zu schwankenden Kontrasten zwischen Tierkörper und Hintergrund führen. Um den Kontrast anzupassen, können verschiedene Schritte unternommen werden:
- Kontrastanpassung
- Histogramm-basierte Optimierung
- ggf. adaptive Kontrastverstärkung
- CLAHE (Kontrastoptimierung)
Rauschunterdrückung: Bildrauschen und Kompressionsartefakte beeinflussten die Stabilität der Maskenbildung. Dieses Rauschen kann u.a. durch MedianBlur, BilateralFilter und GaussianBlur reduziert werden.
Kanten- und Struktur:
-
Zur Hervorhebung relevanter Objektkonturen kann ein Canny-Filter eingesetzt werden, der eine präzise Detektion der Tierumrisse ermöglicht.
- Ergänzend können Sobel-Filter verwendet werden, um lokale Intensitätsänderungen und strukturelle Details im Bild hervorzuheben.
- Zur Trennung von Objekt- und Hintergrundbereichen kann das Otsu-Schwellenwertverfahren eingesetzt werden, das einen global optimalen Schwellenwert basierend auf der Intensitätsverteilung bestimmt.
- Zusätzlich kann adaptives Thresholding eingesetzt werden, welches lokale Schwellenwerte berechnet und somit besonders bei inhomogener Beleuchtung robuste Segmentierungen ermöglicht.




Objekterkennung (Detection)
In diesem Schritt identifiziert die KI automatisch das relevante Objekt im Bild – beispielsweise die Ziege – und lokalisiert es innerhalb der Aufnahme. Dadurch wird gewährleistet, dass die weiteren Verarbeitungsschritte ausschließlich auf das erkannte Objekt angewendet werden.
Zur automatisierten Lokalisierung der Ziege wurde ein YOLO-basiertes Objekterkennungsmodell eingesetzt. Erste Experimente zeigen eine stabile Detektion auch bei variierenden Hintergrundstrukturen. Die Bounding-Box-Genauigkeit wurde anhand manuell annotierter Referenzdaten evaluiert.

Segmentierung
Hier wird das Bild in bedeutungsvolle Bereiche unterteilt – beispielsweise in Tierkörper, Hintergrund oder relevante Messpunkte. Ziel ist es, Objekte klar voneinander abzugrenzen.
Dafür müssen mintunter die Bilder nochmals nachbearbeitet werden, weil die Segmentierungsmasken vereinzelt kleine Fehlbereiche oder fragmentierte Strukturen enthielten.
Nach der Maskenstabilisierung können die Bilder in Bereiche "segmentiert" werden, die für die spätere Analyse relevant sind. Im Fall von PowerAImage ging es vorrangig darum, die Tierkörper vom Bildhintergrund zu trennen.



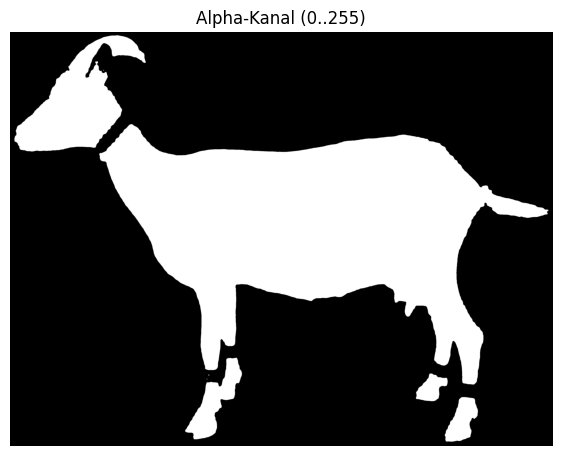

Merkmalsextraktion
Aus den segmentierten Bereichen werden messbare Eigenschaften gewonnen – etwa Abstände, Formen oder Temperaturmuster.
1. Geometrie (in Enwticklung)
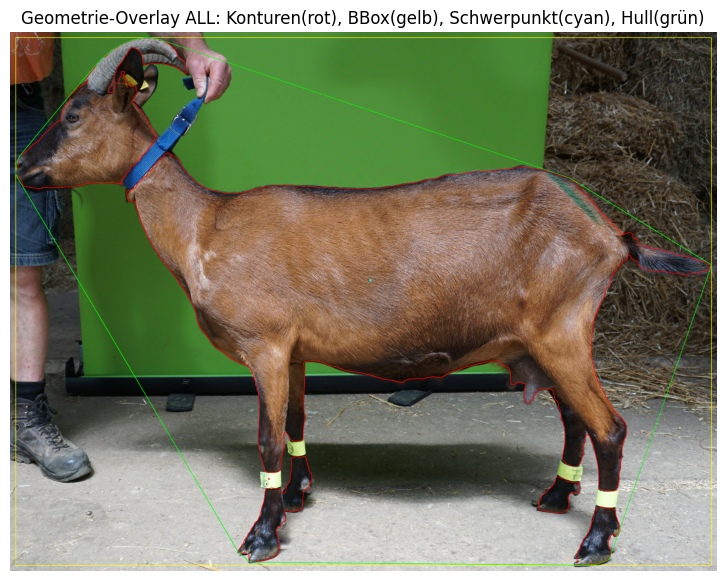
Auf Basis der segmentierten Tiermaske werden definierte Referenzpunkte automatisch identifiziert. Zwischen diesen Punkten werden geometrische Abstände berechnet, die als Grundlage für weiterführende Analysen dienen. Auf Basis von 2D-Aufnahmen können die Werte nur geschätzt werden. Exaktere Berechnungen können mithilfe von Tiefenkamerabildern erfolgen.
Zunächst werden die geometrischen Messungen in Pixelkoordinaten berechnet.
- Skalierungsfaktor zur Umrechnung Pixel → reale Maße
- Koordinatenbasierte Distanzberechnung
Auf dieser Grundlage lassen sich dann relevante Parameter berechnen wie:
- Körperlänge
- Winkel
- Proportionen
- Distanzmessung
- Skalierung
Pipeline zur Detektion und Vermessung von Markierungsringen an den unteren Extremitäten: Zunächst wird eine Region of Interest (ROI, relevanter Bildausschnitt) definiert (Bild 1). Anschließend erfolgt die Segmentierung potenzieller Ringbereiche mittels Farb-Thresholding (Farbschwellenwertverfahren) (Bild 2). Die resultierende Maske wird bereinigt, um Störpixel zu entfernen (Bild 3). Darauf aufbauend werden Ringkandidaten identifiziert und durch Bounding-Boxen (umgebende Rechtecke) lokalisiert (Bild 4). Abschließend wird die vertikale Ausdehnung der Ringe gemessen (Bild 5) und in Pixel sowie reale Maßeinheiten umgerechnet (Bild 6).





2. Skelett (in Entwicklung)
Skelettbasierte Analyse:
- Keypoints
- Achsen
- Strukturmodell
